代表値と散布度
代表値と散布度
統計データの特徴を表すために定義された値を代表値 (measure of central tendency) という。
また、データの広がりを表現する量を散布度 (dispersion) という。
以下では、よく使われる代表値と散布度を紹介する。なお、全ての場合において、総数 $n$ のデータ
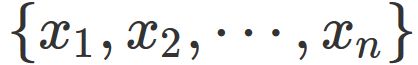
平均値
データ値の総和を総数で割ったものを平均値 $\bar{x}$ という。すなわち、
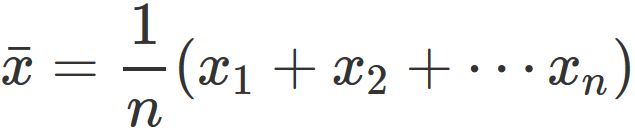
例
総数 $6$ データ $ \{4, 3,6,2,5,1\} $ の平均値は 定義より
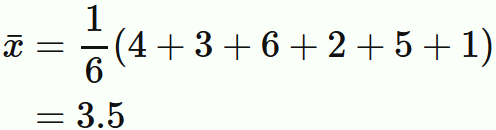 である。
である。
総数 $6$ データ $ \{4, 3,6,2,5,1\} $ の平均値は 定義より
中央値
データが小さい順に、
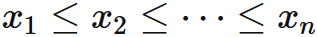
$n$ が奇数の場合には、$\frac{n+1}{2}$ 番目のデータが真ん中に来るので、中央値 $M$ は、
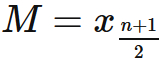
$n$ が偶数の場合には、ちょうど真ん中に来るデータがないので、前半の終わりの値と後半の最初の値の平均値で定義する。 すなわち、
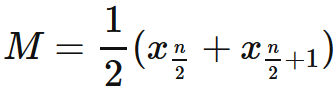
例
$(1)$ 総数 $7$ のデータ
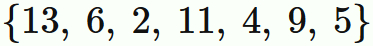 の中央値は、
データを小さい順に並べて
の中央値は、
データを小さい順に並べて
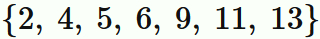 と表し、
総数が $7$ の場合、
中央に来る $4$ 番目のデータ値である。
よって、
と表し、
総数が $7$ の場合、
中央に来る $4$ 番目のデータ値である。
よって、
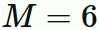 である。
である。
$(2)$ 総数 $8$ のデータ
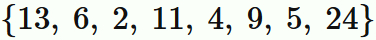 の中央値は、
データを小さい順に並べて
の中央値は、
データを小さい順に並べて
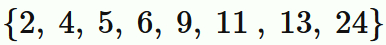 と表し、
総数が $8$ の場合、前半の終わり来るのは $4$ 番目の値であり、
後半の最初に来るのは $5$ 番目の値であるので、
定義から
と表し、
総数が $8$ の場合、前半の終わり来るのは $4$ 番目の値であり、
後半の最初に来るのは $5$ 番目の値であるので、
定義から
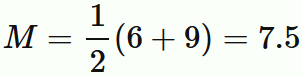 である。
である。
$(1)$ 総数 $7$ のデータ
$(2)$ 総数 $8$ のデータ
最頻値
データの中に最も多くの含まれる値を最頻値 $M_{o}$ という。すなわち、
例
総数 $8$ のデータ
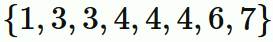 は、
値 $4$ のデータが一番多く含まれるので、
は、
値 $4$ のデータが一番多く含まれるので、
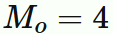 である。
である。
総数 $8$ のデータ
分散
それぞれのデータ $x_{i}$ と 平均値との差の 2 乗 $(x_{i}-\bar{x})^2$ の総和を
総数で割ったものを分散 $\sigma^2$ という。すなわち、
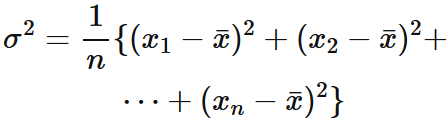
例
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の平均値は
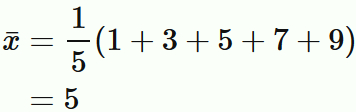 であるので、
分散は、
であるので、
分散は、
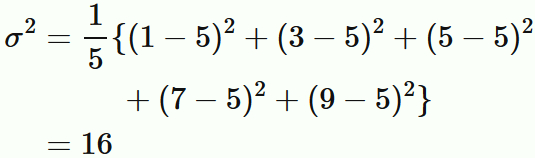 である。
である。
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の平均値は
標準偏差
分散の平方根を標準偏差 $s$ という。すなわち、
\begin{eqnarray}
s &=& \sqrt{\sigma^2}
\\
&=& \sqrt{\frac{1}{n} \{ (x_{1}-\bar{x})^2 + (x_{2}-\bar{x})^2 + \cdots + (x_{n}-\bar{x})^2 \}}
\end{eqnarray}
例
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の分散は 、 \begin{eqnarray} \sigma^2 &=& 16 \end{eqnarray} であるので、 \begin{eqnarray} s &=& \sqrt{\sigma^2} \\ &=& 4 \end{eqnarray} である。
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の分散は 、 \begin{eqnarray} \sigma^2 &=& 16 \end{eqnarray} であるので、 \begin{eqnarray} s &=& \sqrt{\sigma^2} \\ &=& 4 \end{eqnarray} である。
平均偏差
それぞれのデータ $x_{i}$ と 平均値との差の絶対値 $|x_{i}-\bar{x}|$ の総和を、
総数で割ったものを平均偏差 $m_{d}$ という。
すなわち、
$$
m_{d} = \frac{1}{n} ( |x_{1}-\bar{x}| + |x_{2}-\bar{x}| + \cdots + |x_{n}-\bar{x}| )
$$
例
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の平均値は 、 \begin{eqnarray} \bar{x} &=& 5 \end{eqnarray} であるので、 \begin{eqnarray} m_{d} &=& \frac{1}{5} ( |1-5| + |3-5| + |5-5| \\ && \hspace{5mm} + |7-5| + |9-5| ) \\ &=&2.4 \end{eqnarray} である。
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の平均値は 、 \begin{eqnarray} \bar{x} &=& 5 \end{eqnarray} であるので、 \begin{eqnarray} m_{d} &=& \frac{1}{5} ( |1-5| + |3-5| + |5-5| \\ && \hspace{5mm} + |7-5| + |9-5| ) \\ &=&2.4 \end{eqnarray} である。
変動係数
平均値に対する標準偏差の比を変動係数 $c_{v}$ という。すなわち、
$$
c_{v} = \frac{s}{\bar{x}}
$$
例
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の平均値は、 \begin{eqnarray} \bar{x} &=& 5 \end{eqnarray} であり、 標準偏差は、 \begin{eqnarray} s &=& 4 \end{eqnarray} であるので、 変動係数は、 $$ c_{v} = \frac{4}{5} $$ である。
総数 $5$ のデータ $ \{1,3,5,7,9\} $ の平均値は、 \begin{eqnarray} \bar{x} &=& 5 \end{eqnarray} であり、 標準偏差は、 \begin{eqnarray} s &=& 4 \end{eqnarray} であるので、 変動係数は、 $$ c_{v} = \frac{4}{5} $$ である。
補足
総数 $7$ のデータ $$ \{ 1,\hspace{1mm}2,\hspace{1mm}3,\hspace{1mm}4,\hspace{1mm}5,\hspace{1mm}6,\hspace{1mm}609 \} $$ に対する中央値は、 $$ M=4 $$ である。 一方、 中央値ではなく平均値 $A$ を求めると、 \begin{eqnarray} A &=& \frac{1}{7}(1+2+3+4+5+6+609) \\ &=& 90 \end{eqnarray} であり、中央値と比べて極端に大きい。
このように平均値が大きくなった理由は、 データの中にたった一つだけ極端に大きな値 $609$ が含まれるからである。 もしも、 $609$ が何かの測定のミスに由来するノイズである場合には、 平均値の値は、真の値から大きく外れてしまう。
従って、データの中にノイズが含まれる可能性がある場合には、 平均値を算出するよりも、 中央値を用いると、ノイズの影響を軽減し、 真の中心値に近い値を算出することができる。
総数 $7$ のデータ $$ \{ 1,\hspace{1mm}2,\hspace{1mm}3,\hspace{1mm}4,\hspace{1mm}5,\hspace{1mm}6,\hspace{1mm}609 \} $$ に対する中央値は、 $$ M=4 $$ である。 一方、 中央値ではなく平均値 $A$ を求めると、 \begin{eqnarray} A &=& \frac{1}{7}(1+2+3+4+5+6+609) \\ &=& 90 \end{eqnarray} であり、中央値と比べて極端に大きい。
このように平均値が大きくなった理由は、 データの中にたった一つだけ極端に大きな値 $609$ が含まれるからである。 もしも、 $609$ が何かの測定のミスに由来するノイズである場合には、 平均値の値は、真の値から大きく外れてしまう。
従って、データの中にノイズが含まれる可能性がある場合には、 平均値を算出するよりも、 中央値を用いると、ノイズの影響を軽減し、 真の中心値に近い値を算出することができる。